此文是《10周入門資料分析》系列的第16篇
想瞭解學習路線,可以先閱讀 學習計畫 | 10周入門資料分析
上篇介紹了 NumPy,本篇介紹 pandas。
目錄
pandas入門
pandas的資料結構介紹
基本功能
匯總和計算描述統計
處理缺失資料
層次化索引
pandas入門
Pandas 是基於Numpy構建的,讓以NumPy為中心的應用變的更加簡單。
pandas的資料結構介紹
由一組資料(各種 NumPy 資料類型)和一組索引組成: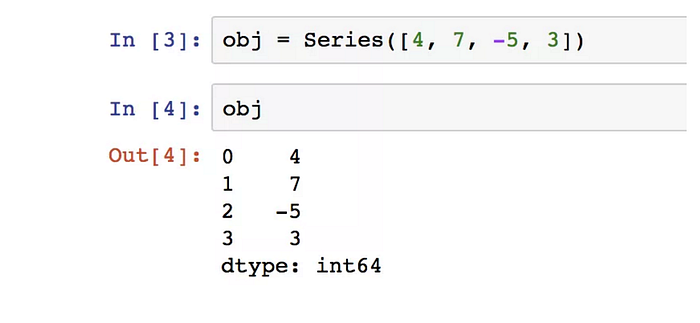
Values 和 index 屬性:
給所創建的Series帶有一個可以對各個數據點進行標記的索引:
與普通NumPy陣列相比,可以透過索引的方式選取Series中的單個或一組值:
可將Series看成是一個定長的有序字典,它是索引值到資料值的一個映射(它可以用在許多原本需要字典參數的函數中)。
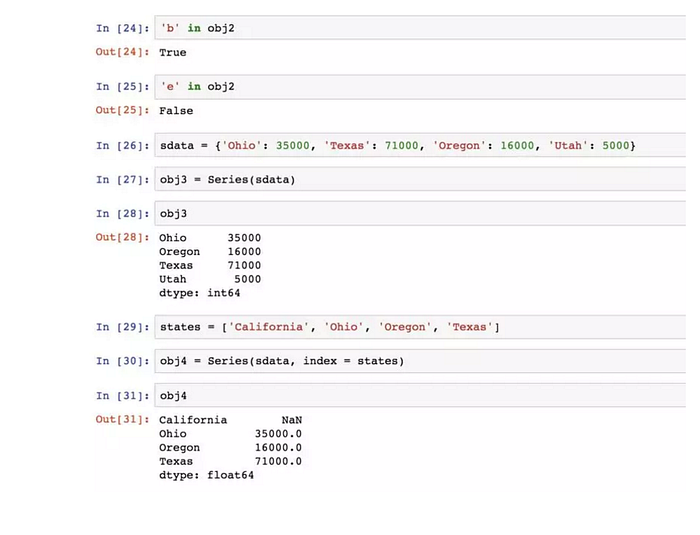
如果資料被存放在一個 python 字典中,可以直接透過這個字典來創建Series:
如果只傳入一個字典,則結果Series中的索引就是原字典的鍵(有序排列),上面的states。
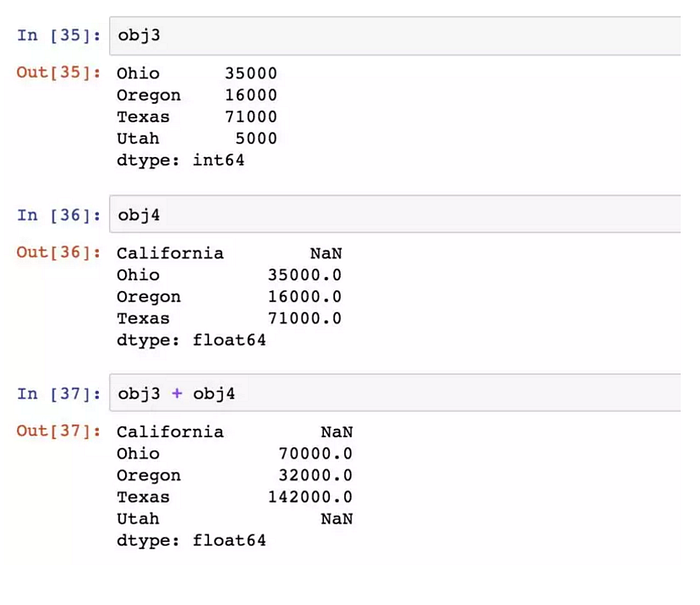
Series最重要的一個功能是在算數運算中自動對齊不同索引的資料:
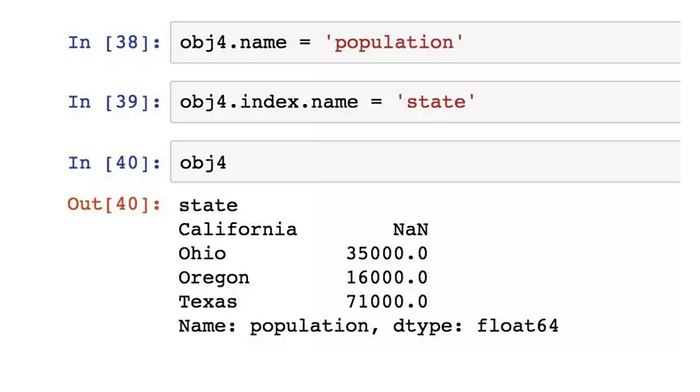
Series物件本身及其索引都有一個name屬性:
Series的索引可以透過賦值的方式就地修改:
是一個表格型的資料結構。既有行索引也列索引。DataFrame中面向行和面向列的操作基本是平衡的。DataFrame中的資料是以一個或多個二維塊存放的。用層次化索引,將其表示為更高維度的資料。
構建 DataFrame:直接傳入一個由等長清單或 NumPy 陣列組成的字典。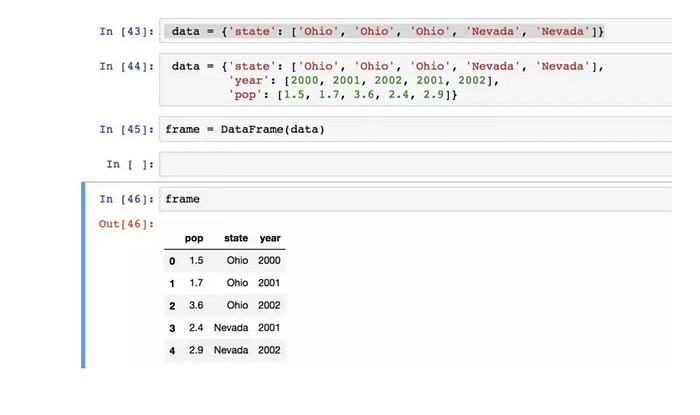
會自動加上索引,但指定列序列,則按指定順序進行排列: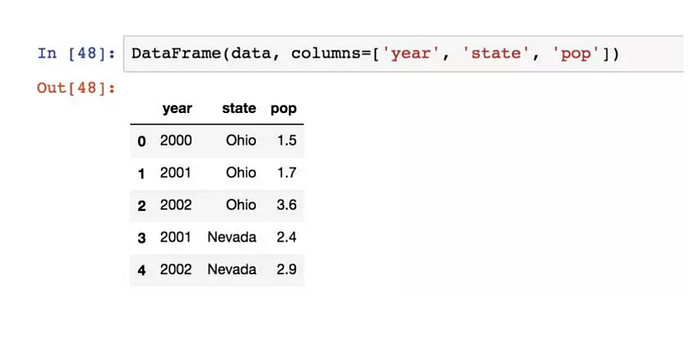
和Series一樣,如果傳入的列在資料中找不到,就會產生NA值:
透過賦值的方式進行修改:
透過類似字典標記的方式或屬性的方式,可以將DataFrame的列獲取為一個Series: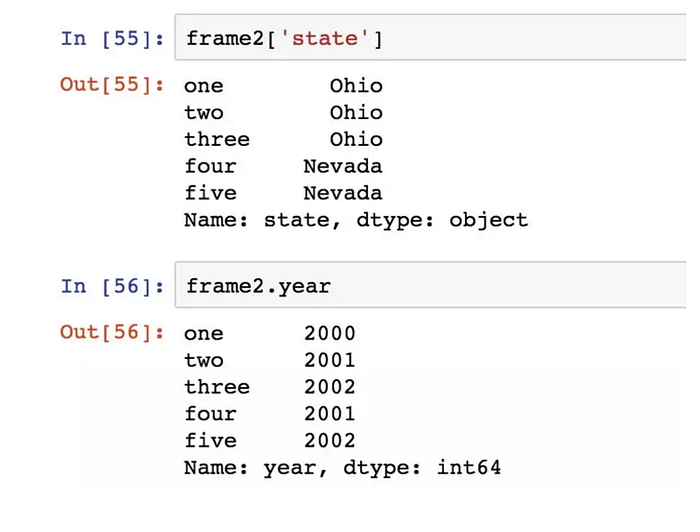
欄也可以透過位置或名稱的方式進行獲取,比如用索引欄位ix。
將清單或陣列賦值給某個列時,其長度必須跟DataFrame的長度相匹配。如果賦值的是一個Series,就會精確匹配DataFrame的索引,所有的空位都將被填上缺失值: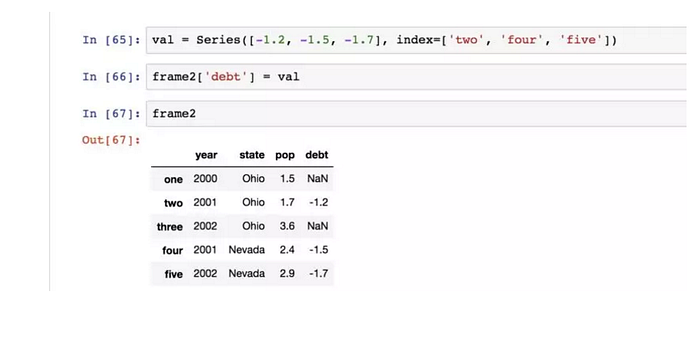
給不存在的列賦值會創建出一個新列,關鍵字del用於刪除列: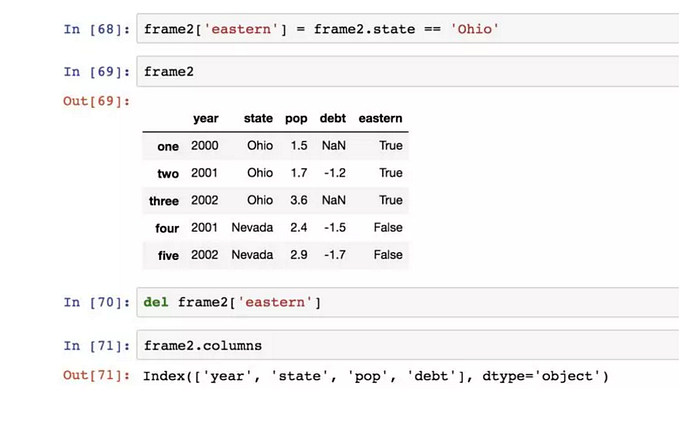
透過索引方式返回的列是相應資料的視圖,並不是副本,對返回的Series做的任何修改都會反映到源DataFrame上,透過series的copy方法即可顯式地複製列。
另一種常見的資料形式是嵌套字典,如果將它傳給DataFrame,解釋為 — — 外層字典的鍵作為列,內層鍵作為行索引。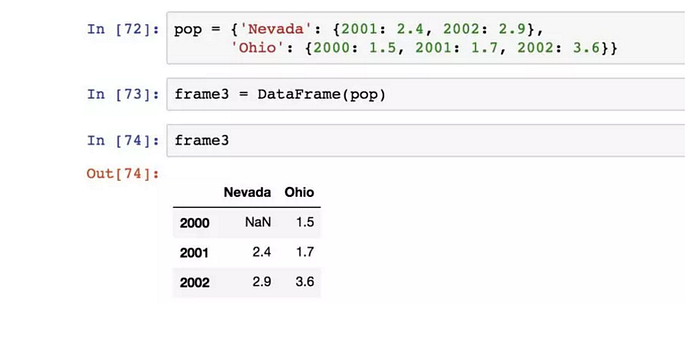
對結果進行轉置:
指定索引按序列:
由Series組成的字典差不多也是一樣的用法:
設定了DataFrame的index和columns的 name 屬性,這些資訊也會被顯示,values 屬性以二維ndarray的形式返回DataFrame中的資料: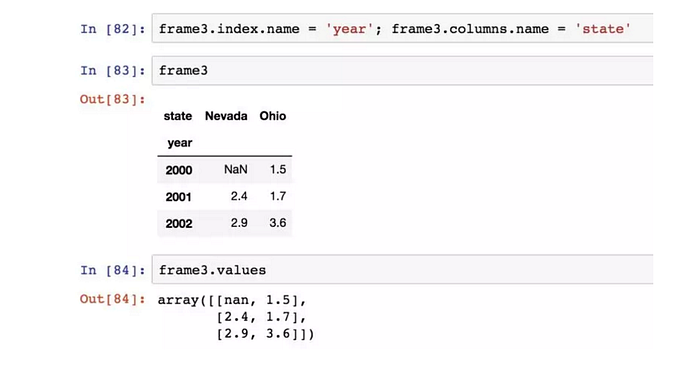
如果DataFrame各列的資料類型不同,值陣列的資料類型就會選用能相容所有列的資料類型(如 dtype = object)。
pandas的索引物件,管理軸標籤和其他中繼資料(如軸名稱等)。
構建Series或DataFrame時,所用到的任何陣列或其他序列的標籤都會被轉換成一個Index,且Index物件是不可修改的: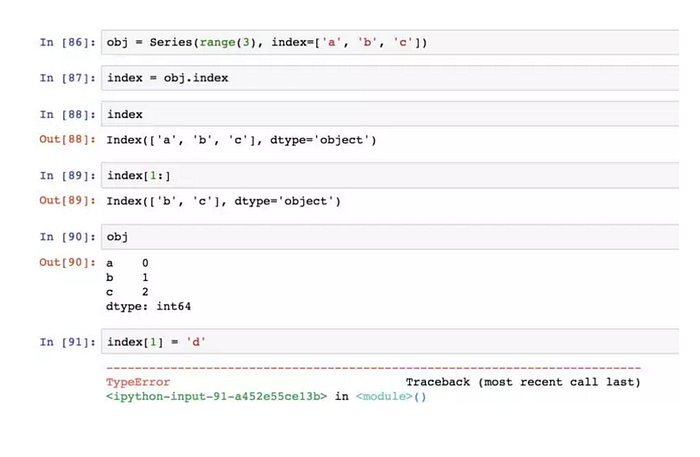
Index的功能類似一個固定大小的集合: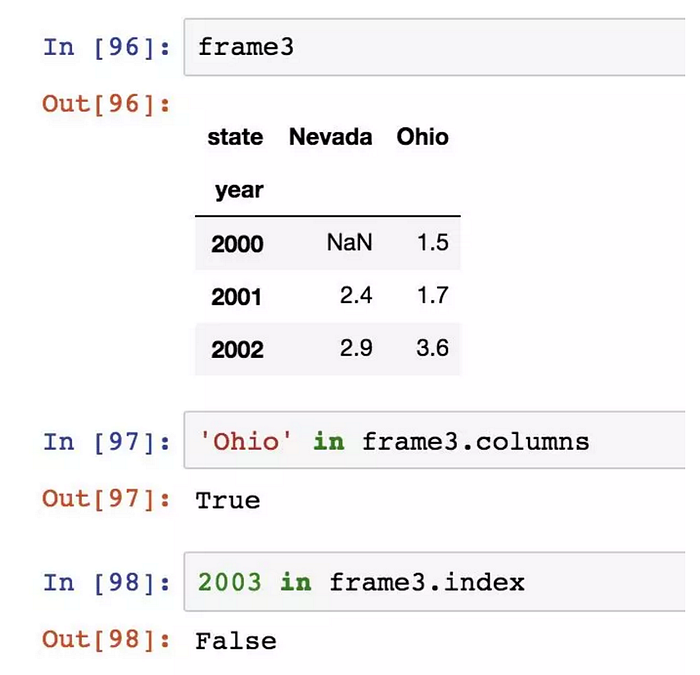
方法 reindex:創建一個適應新索引的新物件。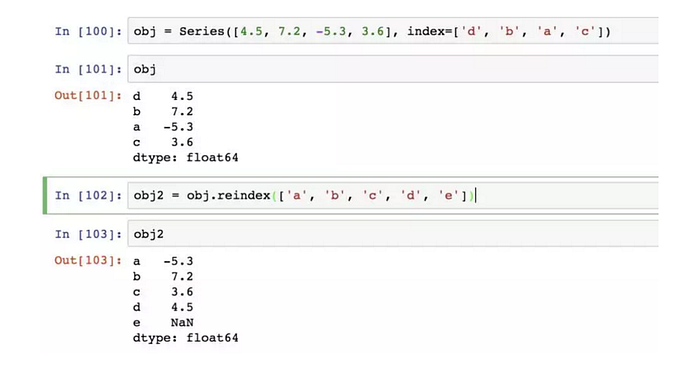
調用該Series的reindex將會根據新索引進行重排。如果某個索引值當前不存在,就引入缺失值。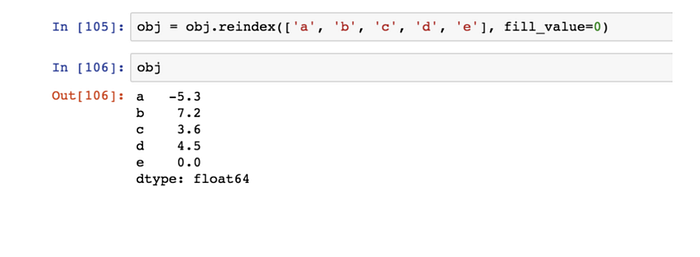
對於時間序列這樣的有序數據,重新索引時可能需要做一些差值處理: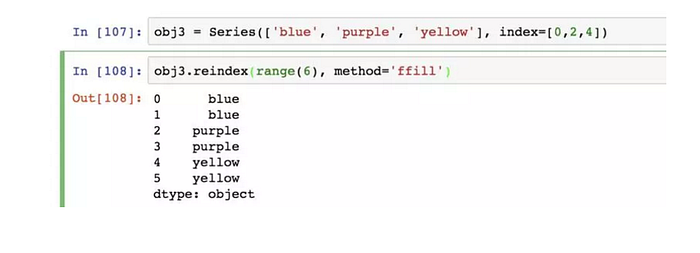
對於DataFrame ,reindex可以修改行、列索引,或兩個都修改。如果僅傳入一列,則會重新索引行: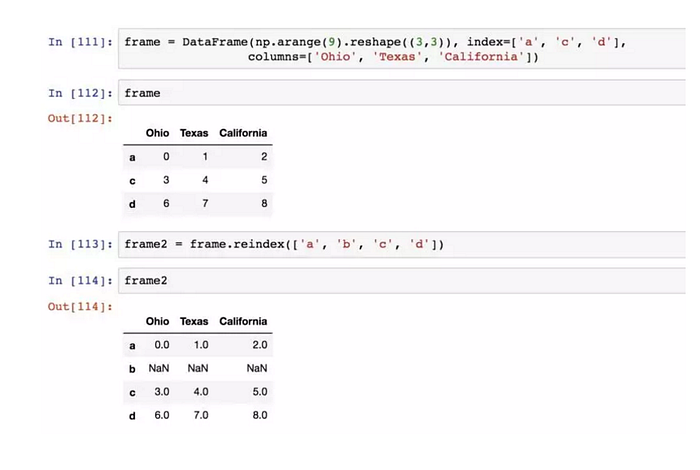
使用columns關鍵字可重新索引列: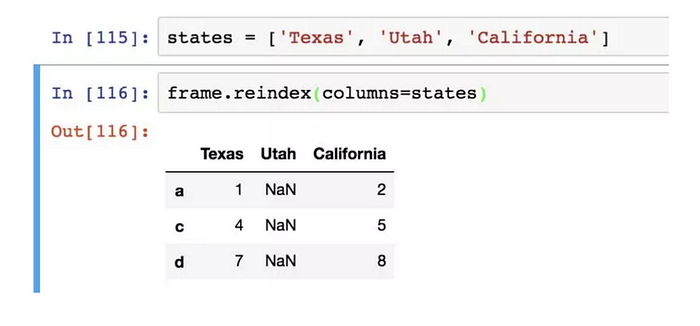
ix標籤索引功能: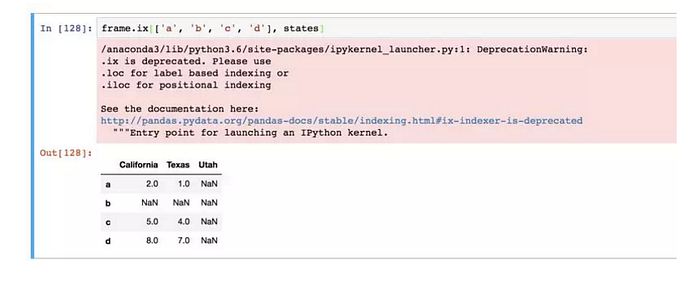
丟棄制定軸上的項
drop方法返回的是一個在指定軸上刪除了指定值的新對象: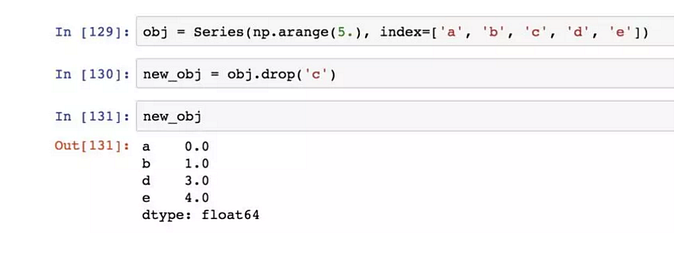
對於DataFrame,可以刪除任意軸上的索引值: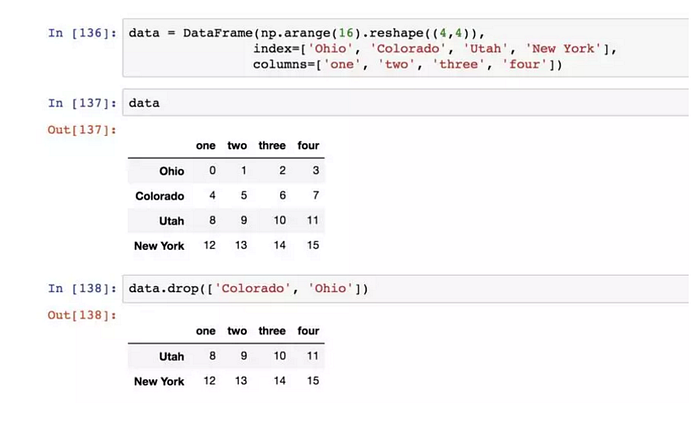

Series索引的工作方式類似於NumPy陣列的索引,但Series的索引值不只是整數:
利用標籤的切片運算,其包含閉區間(與普通 python 切片運算不同):
對DataFrame進行索引就是獲取一個列: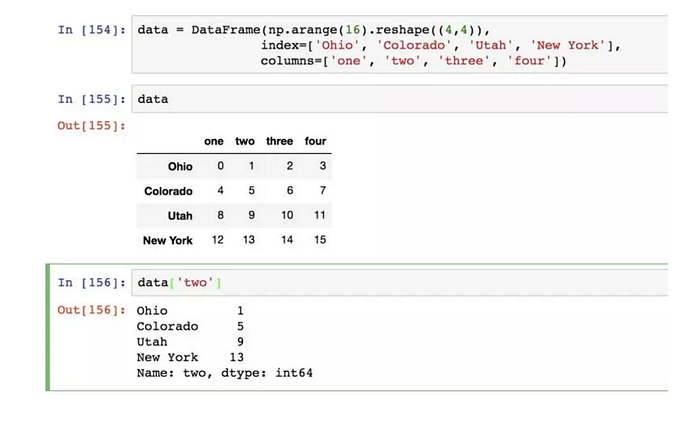
或多個列:
這種索引方式的特殊情況:透過切片或布林型陣列選取行。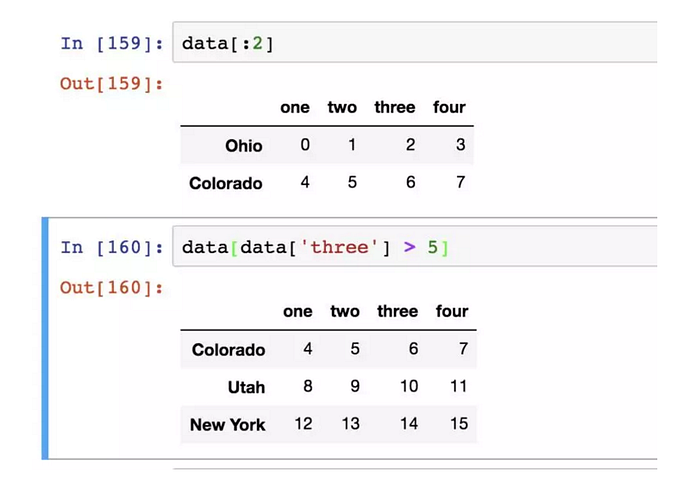
另一種用法是透過布林型DataFrame進行索引(在語法上更像 ndarray):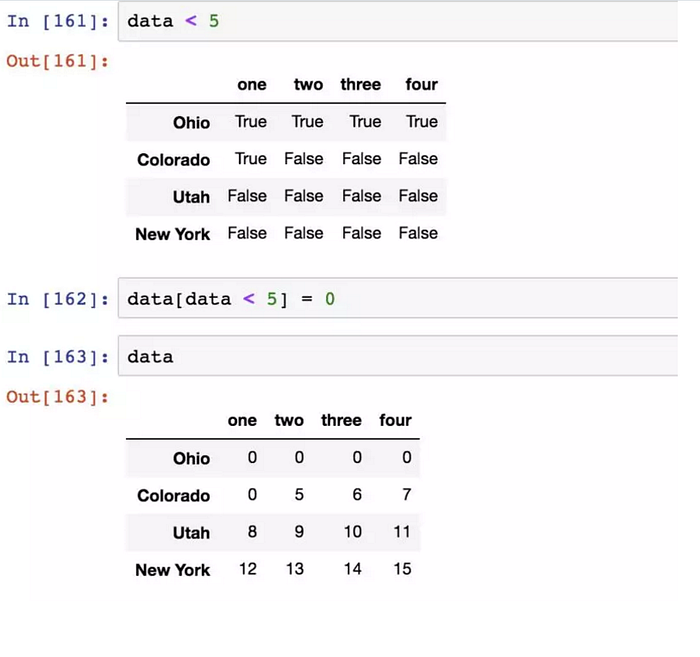
專門的索引欄位 ix,是一種重新索引的簡單手段: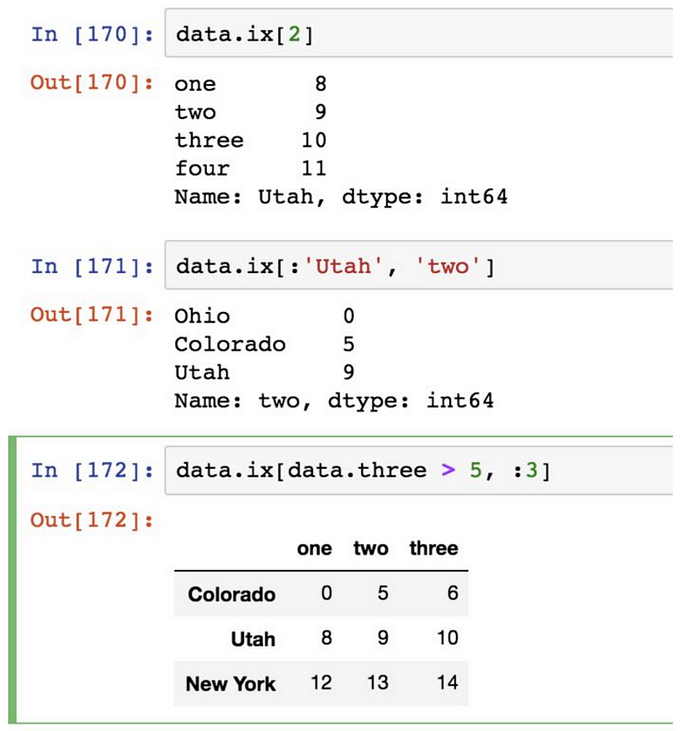
3、算數運算和數據對齊
pandas最重要的一個功能是對不同索引的物件進行算數運算。
對不同的索引對,取並集:
自動的資料對齊操作在不重疊的索引出引入了NA值,即一方有的索引,另一方沒有,運算後該處索引的值為缺失值。
對DataFrame,對齊操作會同時發生在行和列上。
對運算後的NA值處填充一個特殊值(比如 0):
否則 e 列都是NaN值。
類似,在對Series和 DataFrame 重新索引時,也可以指定一個填充值: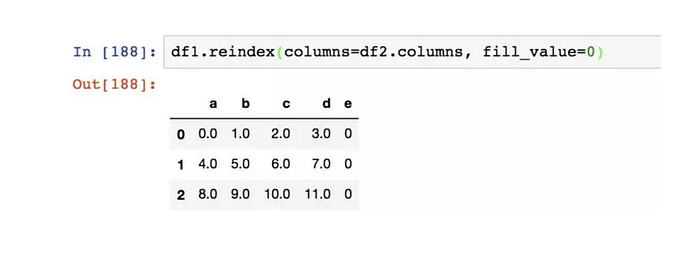
······································
···········································
··············································
·········································
點擊鏈接獲取全文:Python資料分析(四)Pandas
我是「數據分析那些事」。常年分享數據分析乾貨,不定期分享好用的職場技能工具。
已經有2800+的同好按贊我的臉書了,你不來嗎?XD
 groots
groots